
Using Large Datasets
While larger samples provide several benefits (among them increased precision and statistical power, reduced impact of outliers, and better representation of the population under study), they do have their limitations as well. Large data sets can be just as prone to bias or errors as smaller samples - and it is generally harder to identify data quality issues in a large data dump. Without having confidence that the data are representative and without major errors, the results are unreliable at best, and patently wrong at worst.
Fundamentally, the size of data that can be processed in EngineRoom is a function of the working memory available on the browser on your computer and how that data is sent over the internet.
Therefore, in order to not overload browsers and servers, the solution is to sample the data down, while still maintaining statistical integrity.
Sample Your Data
Automatic Random Sampling For Statistical Analysis with EngineRoom
When an .xlsx or .csv dataset is uploaded that exceeds 10MB, EngineRoom offers the ability to sample the data randomly.
Random sampling leaves the shape of the larger dataset intact while reducing the amount of data needed.
For most statistical tools, the required sample size to make sound statistical conclusions is far less than 10MB of data might provide. However, many downloaded data files come with this amount of data.
In higher level statistical model development, random sampling of data is used routinely to develop the model, and the remaining data is used to test the model. This ensures that the model is not overfitting the data as well as providing validation to the model.
EngineRoom uses the reservoir method (which is detailed in this paper) to achieve its random sample, reducing the total dataset size while maintaining statistical integrity.
To randomly sample your data in EngineRoom:
- Click Upload on the data panel.
- Select your file to upload.
- If the file is greater than 10MB, EngineRoom will show an alert asking if you would like to sample your data. Click Sample My Dataset.
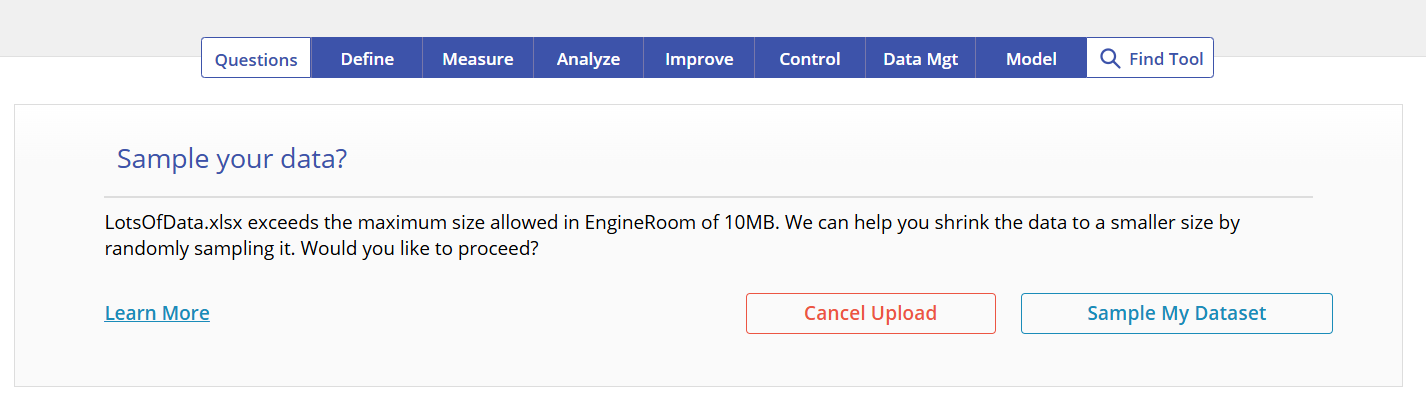
- EngineRoom will automatically sample your data and provide you with a corresponding data source.
Use the variables in this data source in your studies. Please note that large data sources will still have difficulty in the data editor and so we recommend taking a look, but not editing too much!
In addition, studies may take longer to run due to the size of the data.
Reservoir Sampling Method
As stated previously, the size of data that can be processed in EngineRoom is a function of the working memory available in browsers and how that data is sent over the internet.
Therefore, in order to not overload browsers and servers, the solution is to sample the data down.
However, you still have to process all of the data in order to sample it down. So what's the solution without holding all of the data in working memory?
Reservoir sampling.
This method assumes a fixed amount of data will end up in the final set (the reservoir). The algorithm loads in the first set of rows that fill up that reservoir, then each subsequent row of data that exists in the dataset has a random chance of replacing one of the rows in the reservoir. This process continues until all rows of the original dataset have been processed.
The resulting dataset will be a randomly selected sample of data from the original data source.
Each row of data from the original data set will have had an equal probability of appearing in the final data source. This maintains the integrity of random sampling.
For more details on the method, check out this paper here: https://www.cs.umd.edu/~samir/498/vitter.pdf
For a fun, simplified explanation with video, check out this video here: https://www.youtube.com/watch?v=A1iwzSew5QY
Troubleshooting Sampling Failures
On occasion, you may run into cases where we are unable to sample the data for you. When this happens, you will be notified in EngineRoom that your upload failed. The most common cause for failures while sampling a dataset is file formatting. If you have a dataset that fails to sample as a .xlsx file, we recommend saving it in Excel as a .csv file and uploading again. Please note that to sample .csv files, the delimiter must be a comma.
Another common cause for sampling failures is a slow internet connection. We use real-time communication protocols behind the scenes to inform you of the progress of your uploads and stream results back to you. In cases where we are unable to establish a reliable connection to your EngineRoom client, sampling may fail. If you have issues connecting, we recommend first checking your internet connection and trying again.
If you have taken the above troubleshooting steps and are still unable to sample your data successfully, please reach out to our support team for more help.
Limitations
- Stratified Data: If your data has specific groups or populations that you are interested in for your calculation, there is a chance of skewing the groups slightly. With random sampling, you should get a good proportional mix, but because it’s random, it is not guaranteed.
- Outliers: If your dataset has any outliers, it is possible that those will not be present in the final dataset. If the goal of the data analysis is to develop a model, outliers may tend to overfit the model. If the goal of the analysis is to evaluate outliers, you may wish to stratify your datasets into 'outliers' vs 'regular', create independent models, and then compare.
- Hard Limit of 2GB: EngineRoom does impose a technological limit of 2GB on the file size allowed to be uploaded.
Manual Sampling: Random
The most effective way to deal with large data sets is to sample your data appropriately.
1. In Excel, add a column next to your data (in front or at the end).
2. Fill the column with random numbers by putting in "=rand()" in the first cell and copying that information down your sheet by dragging the square handle or double clicking on the square handle.
3. Copy the column of random numbers and Paste Special > Values Only to maintain those numbers.
4. Sort the dataset by the random numbers.
5. From here, you can copy the number of rows from your dataset that makes sense for the type of tool you would like to run.
(This method is adapted from this video beginning at 3:02: https://www.youtube.com/watch?v=LpZqdvaJQAQ)
Manual Sampling: Stratified Random
There are additional considerations if you need to have representative samples from subgroups contained within the data set. This will add a few more steps. You would essentially take a random sample from each subgroup, with the sample size from each subgroup being proportional to the relative size of the subgroup in the larger data set. This ensures that each subgroup is represented in the combined sample.
Copy and Paste
For some smaller data sets, it could be faster to copy and paste your data into EngineRoom.
Try copying a column, or 2 or 3, depending on the number of rows you have.
Alternatively, copy several rows at a time and paste them into EngineRoom. Again, this will depend on the number of columns you have.
Was this helpful?